Artificial Intelligence / Machine Learning
Talk to Me, Anytime, Anywhere
A personal chatbot designed to reflect my personality and, frankly, be me.
Demo
Overview
HenriAI is a fine-tuned conversational model built on GPT-J-6B using QLoRA (4-bit NF4, double quantization) with LoRA adapters on attention and MLP modules. Training uses a curated Q&A/instruction dataset tokenized to 512 tokens, batch size 28, 5 epochs, AdamW + cosine decay, gradient accumulation, and gradient checkpointing; adapters are checkpointed each epoch for A/B selection and rollback. Inference loads the 4-bit base plus adapters via PEFT and serves a FastAPI/Uvicorn API with /generate, /auth, and /healthz; generation supports temperature/top-p and returns latency. Security and integration include server-side password, CORS allowlist to production domains, and exposure to the website via a Cloudflare tunnel with a runtime-injected API URL. Stack: PyTorch, Transformers, PEFT, BitsAndBytes, Accelerate, FastAPI, Uvicorn, Cloudflared, Colab A100.
Technical Highlights
• QLoRA fine-tune of GPT-J-6B (4-bit NF4 + double quant) with LoRA adapters across attention and MLP layers.
• Standardized Q&A/instruction data pipeline at 512-token context for supervised causal training.
• Training regime: AdamW with cosine schedule, gradient checkpointing/accumulation for single-GPU efficiency.
• Versioned LoRA adapter artifacts enabling A/B model selection and rapid rollback.
• Production inference API (FastAPI): /generate with temperature/top-p controls, /healthz; low-latency FP16/AMP decoding.
• Security & integration: server-side auth, strict CORS allowlist, Cloudflare tunnel powering live calls from henriai.ca.
Features
• Fine-tuned GPT-J-6B via QLoRA (4-bit NF4, LoRA on attention + MLP) for conversational Q&A.
• 512-token context encoding with standardized Question/Answer prompt template.
• /generate API with max_new_tokens, temperature, and top_p controls; returns response + latency.
• Mixed-precision (FP16/AMP) decoding with caching for low-latency inference.
• Versioned LoRA adapters (per-epoch) for A/B selection and instant rollback.
• Health & auth endpoints: /healthz and /auth (server-side secret).
• Strict CORS allowlist to production domains; no client-side secret exposure.
• Public access via Cloudflare tunnel; runtime API base injected into the frontend (window.COLAB_API_URL).
Repository
Software Engineering / Mobile Development
Create Your Routine, Your Way
A workout application designed for customizability and user autonomy with elegant UI.
September Update
Why Domyn?
Throughout my fitness journey, I've tested countless workout applications and found them frustrating to use. Most were overly complicated, forcing me into workouts I didn't want to do. They had intrusive advertisements and poor design that completely ruined the experience. When basic functionality was locked behind paywalls, I ended up just using my notes app to track progress. I built Domyn to solve these problems - giving users complete control over their workouts without the BS.
Overview
Domyn is a comprehensive workout application built from the ground up as a solo software engineering project. It empowers users to create fully customized workout routines with complete autonomy over their fitness journey, featuring an elegant and intuitive user interface designed for seamless user experience.
Technical Highlights
Large-Scale Architecture (73,768+ LOC): Modular codebase with 37+ directories including services/, hooks/, utils/, components/, and types/ with 100% TypeScript implementation.
React Native & Expo Stack: Built with React Native 0.79.2, Expo SDK 53, React 19, and Expo Router 5.0 for file-based navigation with typed routes.
Firebase Backend Integration: Complex data modeling with 15+ specialized services, real-time synchronization, and reference-based architecture eliminating data duplication.
Performance Optimization: Custom hook architecture with 50+ specialized hooks, React.useMemo/useCallback throughout, and O(1) exercise history tracking.
Advanced Data Management: Multi-layer caching with EnhancedCacheManager, automatic PR detection across 3 exercise types, and optimistic updates for real-time workout tracking.
Production-Ready Features: Comprehensive error handling with ServiceError system, type-safe constants preventing runtime errors, and Jest testing infrastructure.
Features
Complete Customizability: Users have full control over every aspect of their workout routines.
Intuitive Design: Clean, modern interface that prioritizes user experience and accessibility.
User Autonomy: No restrictions or predefined limitations - build workouts exactly how you want.
Development Journey
Developed entirely as a solo project, showcasing full-stack mobile development capabilities.
Focus on delivering a premium user experience with powerful customization features.
Demonstrates proficiency in UI/UX design, software architecture, and mobile development.
Repository
Mobile Development / Educational Technology
Connect, Learn, Succeed
A comprehensive platform connecting Dalhousie University students with qualified tutors.
Demo
Why DalTutor?
University students often struggle to find qualified tutors who understand their specific coursework and learning needs. Existing tutoring platforms lack university-specific features and fail to build trust between students and tutors. We created DalTutor to solve these problems by providing a dedicated platform for Dalhousie University students to connect with verified peer tutors.
Overview
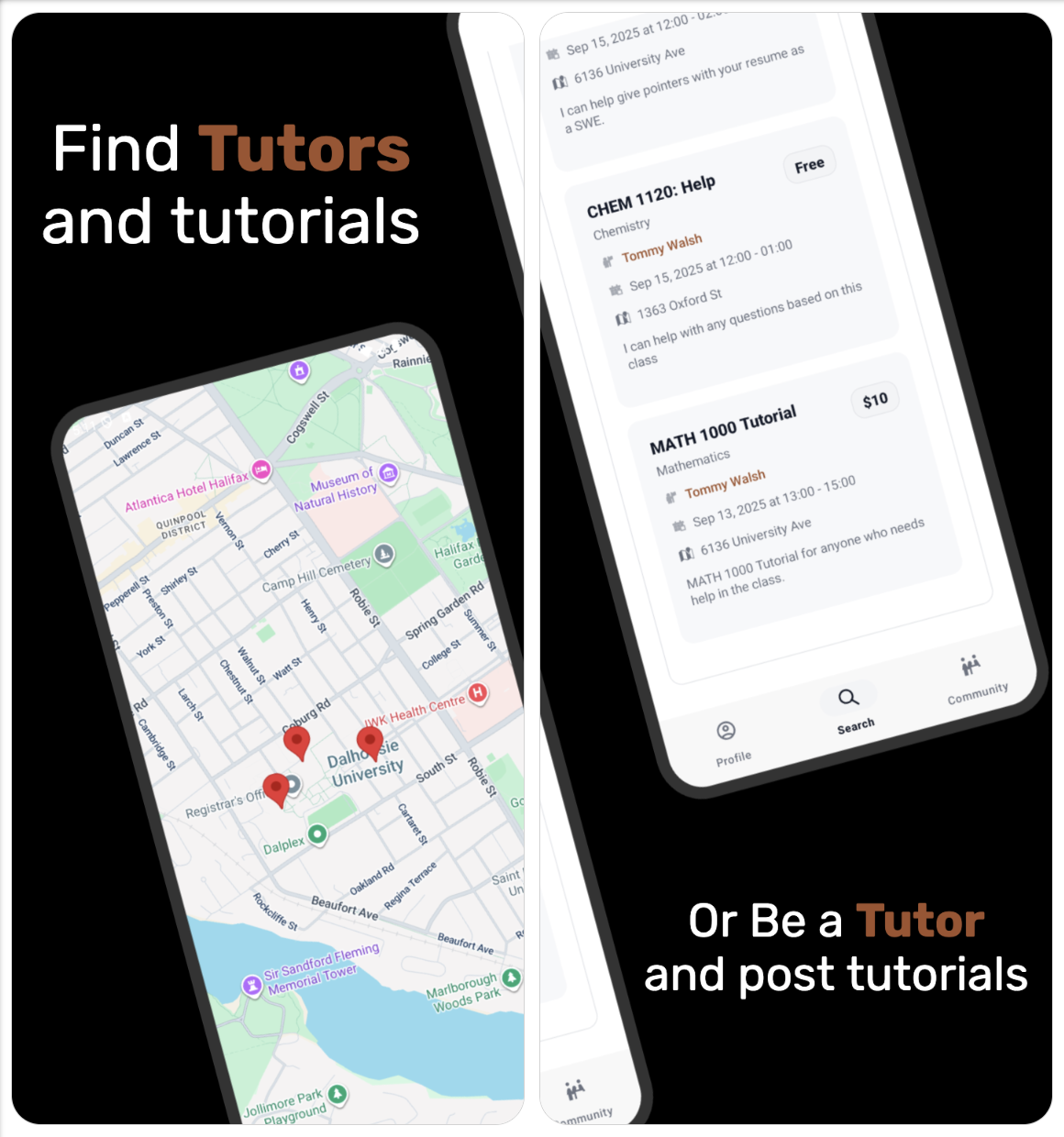
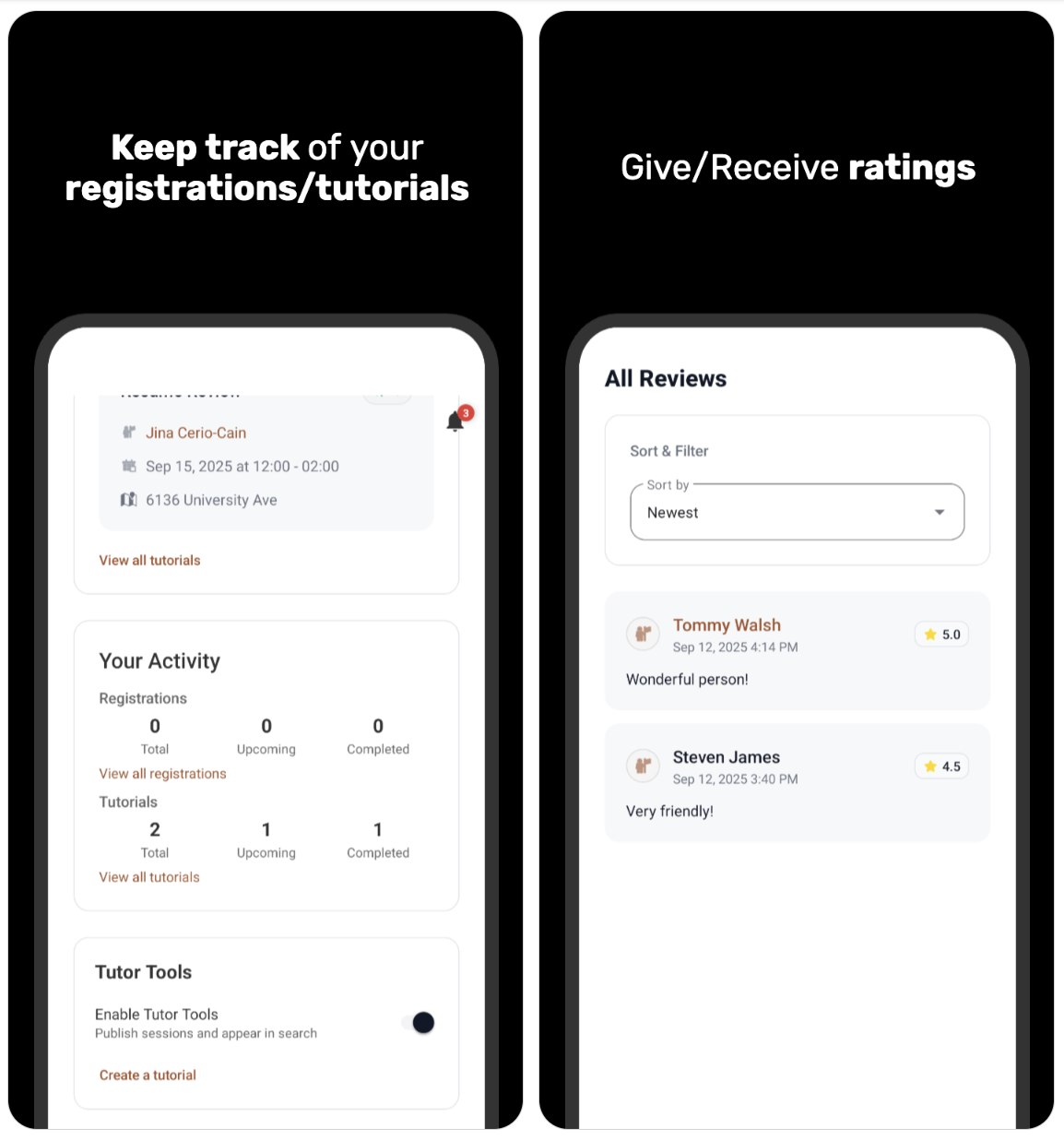
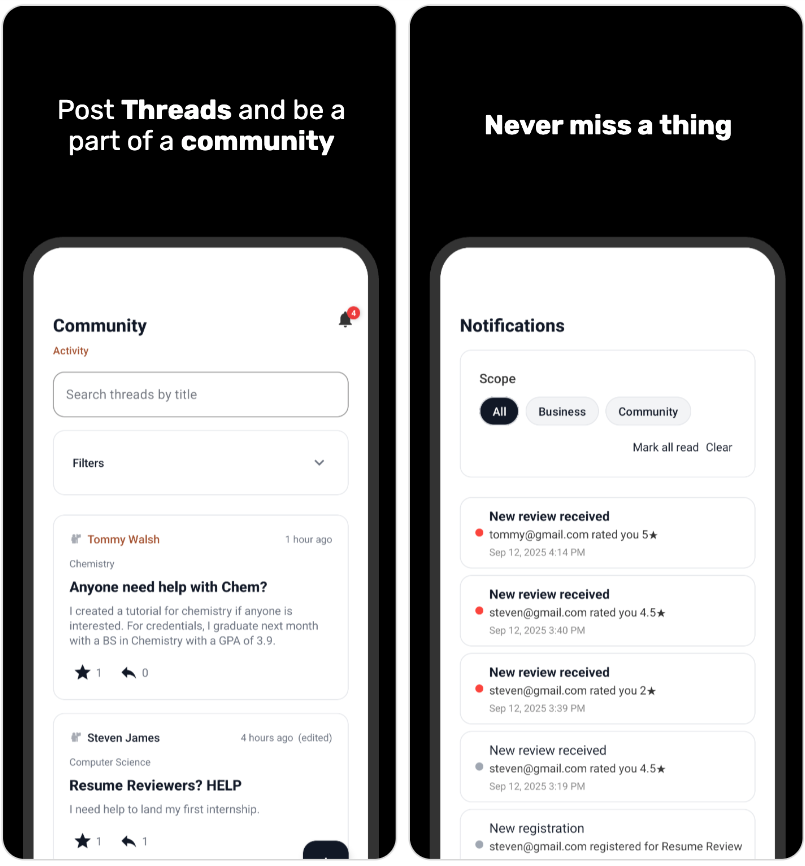
This app is a simple hub that connects students and tutors for on‑campus learning. Students can find the right help by searching for tutorials or tutors by topic, location, fee, degree, or rating, or by browsing a Google Maps view of campus buildings to see what’s happening nearby. Tapping a result opens clear details—time, place, description, capacity, and tutor info—so students can register quickly for free or paid sessions, with integrated payment processing for paid bookings. Tutors can turn on “Tutor Tools” in their profile to post and manage their own tutorials, set the schedule, location and capacity, and see who’s registered. A Community tab lets everyone start threads, reply, and star useful posts, making it easy to share tips and ask questions. Profiles and reviews help students choose confidently, while notifications keep users up to date on registrations and community activity.
Key Features
- Find Tutorials Fast: Search by topic, fee, location, degree, or rating—or browse the campus map.
- One‑Tap Registration: Sign up in seconds; integrated PayPal handles paid sessions smoothly.
- Tutor Tools: Post tutorials with schedule, capacity, fee, and on‑campus location selection.
- Live Availability: See spots left and get real‑time updates as sessions fill.
- Community Threads: Ask questions, share tips, reply, and star helpful posts.
- Profiles & Reviews: View tutor bios, ratings, and recent reviews to choose confidently.
- Smart Notifications: Stay on top of registrations, updates, and community activity.
- Campus Map View: Pins highlight buildings with upcoming sessions; jump straight to location lists.
Technical Highlights
- Location‑Based Discovery (Google Maps SDK): 19 curated DAL buildings, placeId‑based marker grouping, and deep links to location‑specific sessions.
- Faceted Search (MVVM, 6 ViewModels): Topic/location/fee/degree/rating filters with RecyclerView adapter swap for Tutors vs Tutorials and client‑side filtering over cached RTDB snapshots.
- In‑App Payments (PayPal SDK, sandbox): Seamless free/paid registration flow with robust UI state and error handling.
- Realtime UX (Firebase + FCM): ValueEventListener‑driven capacity/listing updates, unified notifications across 2 RTDB nodes with a 99+ unread badge, plus FCM push (NotificationChannel, deep links).
- Data Consistency & Access Control: Atomic multi‑path writes for replies/stars (O(1) write batch), author‑only edits, timestamp‑indexed reads, and guardrails for Tutor Tools (can’t disable with upcoming sessions).
Background
Developed as a collaborative team project showcasing agile development practices and comprehensive feature implementation. Successfully delivered 10+ major user stories including payment integration, location services, and role-based functionality. It began as a group project for my CSCI 3130 Software Engineering course; however, due to technical debt, it was incomplete. I then took initiative to deliver a complete overhaul of the application—end‑to‑end—refactoring the architecture and data model, rebuilding core user flows, paying down technical debt, and adding extensive features, performance improvements, and production‑ready polish.
Binary to RISC Translator
Converts binary code into a streamlined 16-bit RISC instruction set for improved efficiency in embedded systems.
Overview
Cachexx is a binary-to-16-bit RISC instruction set conversion tool. It streamlines data processing for embedded systems by translating binary code into a simplified RISC format, demonstrating low-level programming and instruction set design skills.
Technical Highlights
Binary to RISC Conversion: Creates compact, 16-bit RISC instructions.
Custom Opcode Mapping: Optimizes processing speed and memory usage.
Memory Efficiency: Ideal for resource-constrained systems.
Repository
Document Routing with an RNN
Auto-classifies scanned documents into 4 types (letter, form, email, invoice) using OCR and BiLSTM neural networks for intelligent document routing.
Overview
A document classification system that mirrors real-world document routing workflows used in title and escrow processing. The system leverages OCR to extract text from scanned images, then employs a Bidirectional LSTM (BiLSTM) recurrent neural network to analyze word sequences and classify documents into four categories: letters, forms, emails, and invoices. Built on the RVL-CDIP dataset, this text-only approach demonstrates how sequential models can understand document structure through natural language patterns.
Technical Highlights
OCR Pipeline: Pytesseract (Tesseract wrapper) integration converts scanned images to text, preserving document structure through sequential word order.
BiLSTM Architecture: Bidirectional LSTM (128 hidden units) reads text both forward and backward to capture contextual relationships in document headers, lines, and signatures.
Text Processing Pipeline: Keras TextVectorization layer with 20K vocabulary, 300-token sequences, and padding/truncation for consistent input dimensions across all documents.
Training Pipeline: 4000 training samples across 4 balanced classes, 3 epochs with AdamW optimizer, achieving ~83% test accuracy on 476 validation samples.
Real-Time Prediction: predict_image() function accepts unseen scanned pages, performs OCR + tokenization, and returns class + confidence scores for production deployment.
Production-Ready Dataset: RVL-CDIP streaming from Hugging Face with per-class sampling (1000 train, 120 test per category) for balanced model performance.
Features
Multi-Class Classification: Accurately distinguishes between 4 document types with softmax activation for probabilistic predictions.
RNN-Based Understanding: BiLSTM captures sequential patterns in document text, understanding context that simple bag-of-words models miss.
Real-World Dataset: Trained on RVL-CDIP, a public dataset of real scanned documents, ensuring practical applicability.
Inference API: predict_image() function accepts PIL images, performs OCR, tokenization, and returns class prediction with confidence scores.
Validation Metrics: Comprehensive evaluation with accuracy tracking, confusion matrix support for error analysis.
Why RNN/Text-Only?
OCR extracts structured text that LSTMs can process sequentially, capturing document flow (headers → body → signatures). This text-only approach keeps the model simple and interpretable without requiring complex computer vision transformers, while still achieving strong classification performance by leveraging the inherent sequential nature of document content.